AIAgent - LiteLLM
2026.02.26
林嘉伟
系列文章:
- AIAgent - 简易框架搭建
- AIAgent - LiteLLM
- AIAgent - 流式输出与视觉支持
- AIAgent - MCP
- AIAgent - SKILLS
上篇文章讲了如何用智谱的api搭建一个简单的ai agent,但各家llm的api多多少少都会有一些差异,是否意味着我们要一家家对接过去呢?
其实业界早就有LiteLLM这种兼容各家api的统一调用库,我们只需要对接liteLLM就能通过简单的配置切换种llm的api。
LiteLLM SDK
LiteLLM基本上是按照OpenAI的接口设计的,而智谱的接口也和OpenAI一致,所以改成使用LiteLLM改动其实很小:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| from litellm import completion
from agent_memory import AgentMemory
from tool.tool_manager import ToolManager
class AgentBrain:
def __init__(self, llm_config: dict, memory: AgentMemory, tool_manager: ToolManager):
self._model = llm_config["model"]
self._api_key = llm_config["api_key"]
self._memory = memory
self._tools_definition = tool_manager.get_tool_definition()
def think(self, prompt):
try:
self._memory.add_user_prompt(prompt)
message = completion(
model = self._model,
messages = self._memory.get_memory(),
tools=self._tools_definition,
api_key=self._api_key,
).choices[0].message
self._memory.add_agent_response(message)
return message
except Exception as e:
return f"思考过程出错: {e}"
|
从文档来看模型的选择需要加上zai/前缀,然后就可以使用completion去调用功能请求了(api_key通过参数传入),它的响应格式也是按着OpenAI来的。
由于各家的api并不是完全一样的,所以completion调用不同llm的时候支持的参数也有所差异,根据文档,我们可以用get_supported_openai_params去查询支持的参数:
1
2
3
4
5
| from litellm import get_supported_openai_params
response = get_supported_openai_params(model="zai/glm-4.7", custom_llm_provider="zai")
print(response)
|
然后agent用到的函数调用的功能可以参考这个文档,也不是所有llm都支持的,可以通过supports_function_calling查询是否支持:
1
2
3
4
5
| from litellm import supports_function_calling
response = supports_function_calling(model="zai/glm-4.7")
print(response)
|
LiteLLM Proxy
除了统一API接口之外LiteLLM还有个企业里常用的功能就是LLM网关,通过下面命令安装启动:
1
2
3
4
| pip install 'litellm[proxy]'
# config文件参考官方文档https://docs.litellm.ai/docs/proxy/configs
litellm --config config.yaml
|
比如企业为员工购买token,总不能直接将原始的API Key发给员工,这个时候就可以用LiteLLM Proxy创建一个虚拟的API Key,所有权限、预算和限制都绑定在虚拟密钥上,极大提升了安全性。
启动proxy之后可以在http://0.0.0.0:4000/看到一堆的api,例如获取所有配置的模型:
1
2
| $ curl http://0.0.0.0:4000/models
$ {"data":[{"id":"glm","object":"model","created":1677610602,"owned_by":"openai"}],"object":"list"}
|
然后就可以用虚拟的key,例如我这里的sk-1234去请求glm的模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| $ curl -X POST http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "glm",
"messages": [
{
"role": "user",
"content": "你好!"
}
]
}'
$ {"id":"202602262339573cc26ce0b8804062","created":1772120400,"model":"glm","object":"chat.completion","choices":[{"finish_reason":"stop","index":0,"message":{"content":"你好!😊 很高兴见到你!有什么可以帮您的吗?无论是问题、建议还是闲聊,我都很乐意为
您服务~","role":"assistant","reasoning_content":"\n嗯,用户发来了一个简单的问候“你好!”。这看起来像是一个初次接触的开场白,可能用户刚进入对话界面,或者想测试系统是否在线。 \n\n用户没有附带任何具体问题或需求,所以我的回复应该保持友好且开放,鼓励ta进
一步表达需求。考虑到中文用户的习惯,用“你好!”回应比较自然,同时加上表情符号可以增加亲和力——毕竟纯文字对话容易显得生硬。 \n\n后续可以主动询问需要什么帮助,但避免过度追问给用户压力。用“有什么可以帮您的吗?”这种开放式提问,比“您有什么问题?”更柔和。 \n\n对了,用户没提供任何背景信息,所以暂时不需要预设ta的技术能力或使用场景,保持通用性即可。如果ta后续提出具体问题,再调整回
复深度。","provider_specific_fields":{"refusal":null,"reasoning_content":"\n嗯,用户发来了一个简单的问候“你好!”。这看起来像是一个初次接触的开场白,可能用户刚进入对话界面,或者想测试系统是否在线。 \n\n用户没有附带任何具体问题或需求,所以我的回复应该
保持友好且开放,鼓励ta进一步表达需求。考虑到中文用户的习惯,用“你好!”回应比较自然,同时加上表情符号可以增加亲和力——毕竟纯文
字对话容易显得生硬。 \n\n后续可以主动询问需要什么帮助,但避免过度追问给用户压力。用“有什么可以帮您的吗?”这种开放式提问,比“您有什么问题?”更柔和。 \n\n对了,用户没提供任何背景信息,所以暂时不需要预设ta的技术能力或使用场景,保持通用性即可。如果ta后续提出具体问题,再调整回复深度。"}},"provider_specific_fields":{}}],"usage":{"completion_tokens":201,"prompt_tokens":7,"total_tokens":208,"prompt_tokens_details":{"cached_tokens":4}},"request_id":"202602262339573cc26ce0b8804062"}
|
我们可以使用/user/xxx的接口去管理用户:
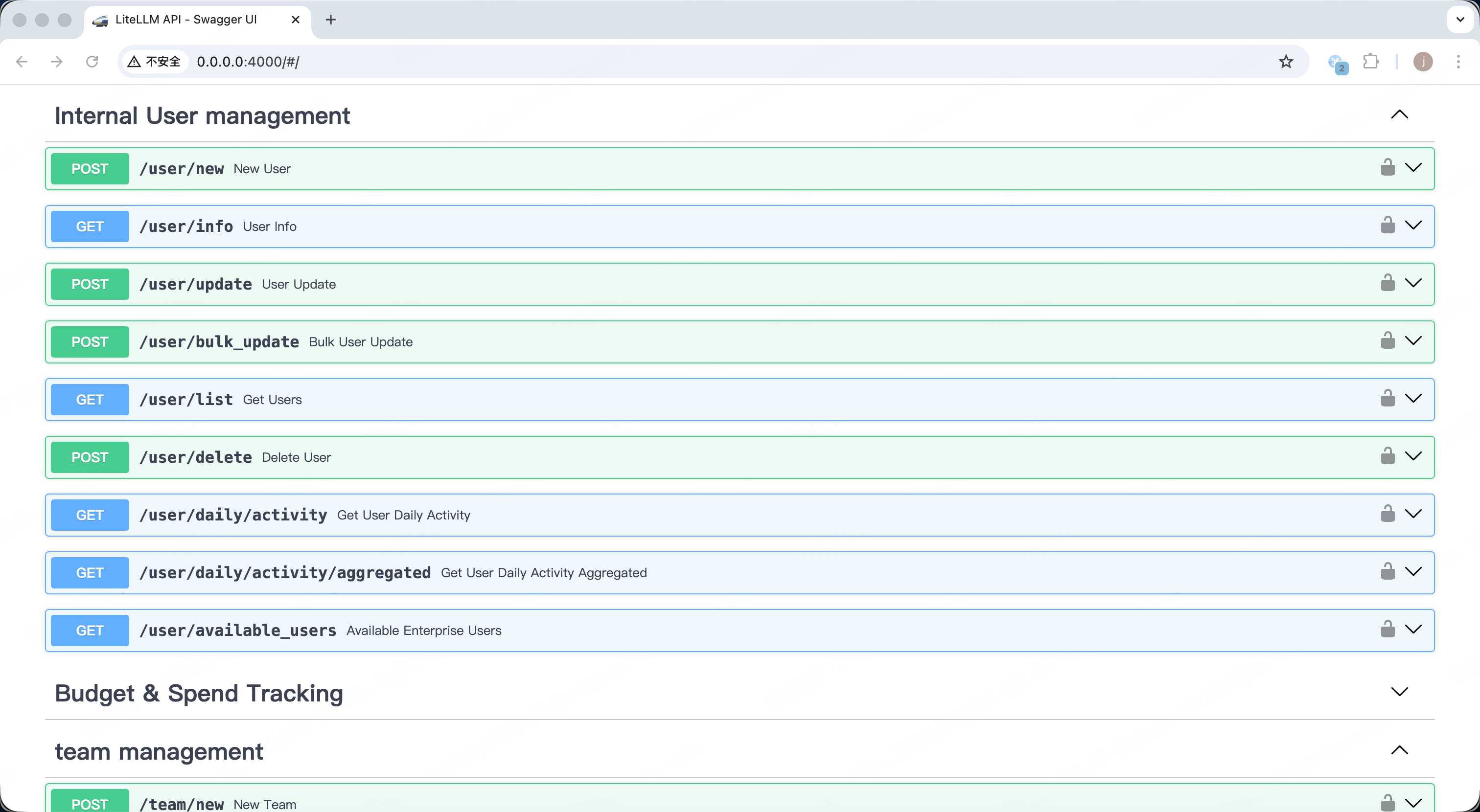
和使用/key/xxx的接口去管理虚拟key(例如用/key/generate为用户创建一个key):
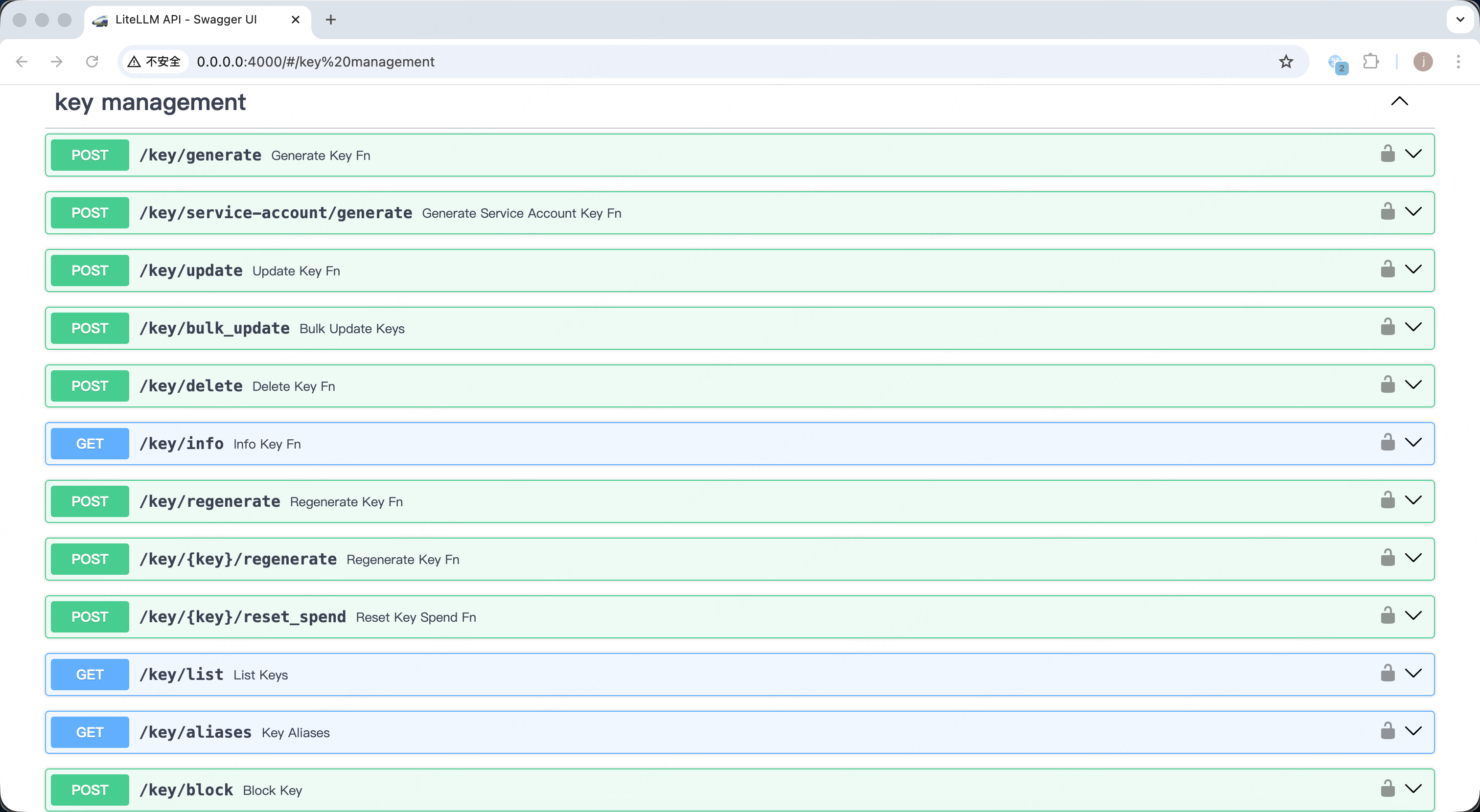
然后就可以在虚拟密钥、用户、团队或模型层级设置月度、每日等周期性预算,实时监控和记录每个 API 调用的成本,帮助企业精准控制开支,还可以做速率限制与流量控制。