系列文章:
接着上篇笔记 ,按照Glide的流程查询完内存缓存之后应该算是查询磁盘缓存,但是由于磁盘缓存的数据依赖第一次请求的时候从网络下载,再写入磁盘缓存。所以我这篇先讲网络请求部分的流程。
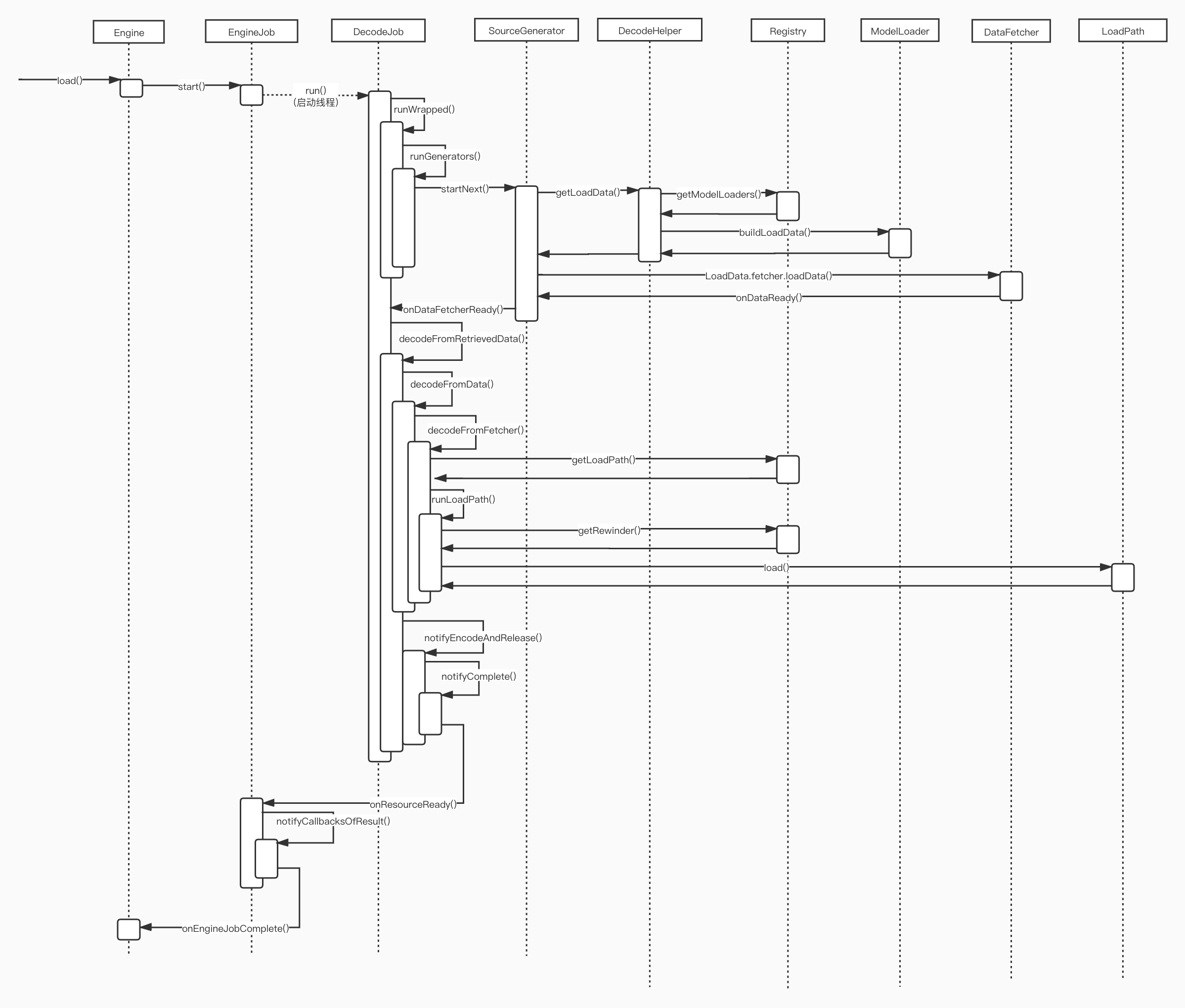
这部分的代码坦白讲比较多也比较绕,我在看的时候也看的头晕。这里就不去把代码都列出来了,感兴趣的同学可以跟着下面的时序图去追踪一下:
EngineJob的功能比较简单,就是管理加载和回调:
1 2 3 4 5 6 7 class EngineJob <R> implements DecodeJob .Callback<R>, Poolable { ... }
它最重要的功能是启动了DecodeJob去加载资源,DecodeJob是一个运行在子线程的Runnable。它会使用Generator去从缓存或者数据源加载数据,我们这次只看从数据源加载的SourceGenerator。
SourceGenerator在启动的时候会使用DecodeHelper去获取一个叫LoadData的东西,这一步比较有意思我们展开讲,先看看DecodeHelper.getLoadData的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 List<LoadData<?>> getLoadData() { if (!isLoadDataSet) { isLoadDataSet = true ; loadData.clear(); List<ModelLoader<Object, ?>> modelLoaders = glideContext.getRegistry().getModelLoaders(model); for (int i = 0 , size = modelLoaders.size(); i < size; i++) { ModelLoader<Object, ?> modelLoader = modelLoaders.get(i); LoadData<?> current = modelLoader.buildLoadData(model, width, height, options); if (current != null ) { loadData.add(current); } } } return loadData; }
loadData是个List,而且DecodeHelper内部做了缓存。它的加载逻辑是先用model(就是我们load传入的url)从glideContext里面查询ModelLoader列表,然后遍历它去buildLoadData丢到loadData这个列表里面。
ModelLoader的查询与注册 getModelLoaders的逻辑很简单,就用modelLoaderRegistry去getModelLoaders:
1 2 3 4 @NonNull public <Model> List<ModelLoader<Model, ?>> getModelLoaders(@NonNull Model model) { return modelLoaderRegistry.getModelLoaders(model); }
modelLoaderRegistry里面会根据model的class查询modelLoaders列表,然后遍历它去使用ModelLoader.handles方法判断这个ModelLoader是否支持这个model,如果是的再放到filteredLoaders里面一起返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public <A> List<ModelLoader<A, ?>> getModelLoaders(@NonNull A model) { List<ModelLoader<A, ?>> modelLoaders = getModelLoadersForClass(getClass(model)); ... int size = modelLoaders.size(); boolean isEmpty = true ; List<ModelLoader<A, ?>> filteredLoaders = Collections.emptyList(); for (int i = 0 ; i < size; i++) { ModelLoader<A, ?> loader = modelLoaders.get(i); if (loader.handles(model)) { if (isEmpty) { filteredLoaders = new ArrayList <>(size - i); isEmpty = false ; } filteredLoaders.add(loader); } } ... return filteredLoaders; }
这个逻辑要怎么理解呢?举个例子,就是假设model是一个Uri,那么getModelLoadersForClass查出来的ModelLoader列表里面可能有加载本地图片的也可能有加载网络图片的。然后分别调用ModelLoader.handles方法去过滤。如果是个本地请求的Uri,网络请求的ModelLoader就会被过滤掉,因为它只支持http和https的scheme:
1 2 3 4 5 6 7 8 9 10 public class UrlUriLoader <Data> implements ModelLoader <Uri, Data> { private static final Set<String> SCHEMES = Collections.unmodifiableSet(new HashSet <>(Arrays.asList("http" , "https" ))); ... @Override public boolean handles (@NonNull Uri uri) { return SCHEMES.contains(uri.getScheme()); } ... }
getModelLoadersForClass方法里面也比较绕,我就不展开代码了,只要知道它是根据model的class去查询即可。
有了查询就肯定有注册,它的注册在Glide的构造函数里面有很长的一坨,第一个参数就是用于对比model class的,第二个参数是DataFetcher的数据类型,最后一个参数是ModelLoader的工厂:
1 2 3 4 5 6 7 8 9 10 registry ... .append(String.class, InputStream.class, new StringLoader .StreamFactory()) ... .append(Uri.class, InputStream.class, new UriLoader .StreamFactory(contentResolver)) .append(Uri.class,ParcelFileDescriptor.class,new UriLoader .FileDescriptorFactory(contentResolver)) .append(Uri.class,AssetFileDescriptor.class,new UriLoader .AssetFileDescriptorFactory(contentResolver)) .append(Uri.class, InputStream.class, new UrlUriLoader .StreamFactory()) .append(URL.class, InputStream.class, new UrlLoader .StreamFactory()) ...
光看这个流程其实还比较好理解,但是由于我们使用的是String类型的url,当我第一次追踪代码的时候还是有被绕晕。原因是String.class注册的StringLoader自己并不干活,而是将String转换成Uri再去registry里面找人干活:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class StringLoader <Data> implements ModelLoader <String, Data> { public StringLoader (ModelLoader<Uri, Data> uriLoader) { this .uriLoader = uriLoader; } @Override public LoadData<Data> buildLoadData (@NonNull String model, int width, int height, @NonNull Options options) { Uri uri = parseUri(model); if (uri == null || !uriLoader.handles(uri)) { return null ; } return uriLoader.buildLoadData(uri, width, height, options); } @Override public boolean handles (@NonNull String model) { return true ; } ... public static class StreamFactory implements ModelLoaderFactory <String, InputStream> { public ModelLoader<String, InputStream> build (@NonNull MultiModelLoaderFactory multiFactory) { return new StringLoader <>(multiFactory.build(Uri.class, InputStream.class)); } ... } ... }
可以看到StreamFactory创建StringLoader的时候调用了multiFactory.build(Uri.class, InputStream.class)方法创建了一个ModelLoader传给StringLoader。这个build出来的是一个MultiModelLoader,具体细节我也不讲了。它从registry查询了append时候第一个参数为Uri.class,第二个参数为InputStream.class的ModelLoader。
StringLoader.handles直接返回true,然后buildLoadData的时候在从这堆ModelLoader使用handles然后build出来。
也就是相当于将String.class的model转换成了Uri.class类型。但是这样还没有完,Uri.class最终又被转换成了GlideUrl.class,这个我就不展开代码了…
DataFetcher 得到的ModelLoader回到到DecodeHelper.getLoadData去buildLoadData创建LoadData,就得到了一个LoadData列表。
然后SourceGenerator.startNext里面就会遍历这个列表去找到一个能加载资源的LoadData,其中主要干活的是DataFetcher:
1 2 3 4 5 6 7 8 9 10 11 12 13 public boolean startNext () { ... while (!started && hasNextModelLoader()) { loadData = helper.getLoadData().get(loadDataListIndex++); if (loadData != null && (helper.getDiskCacheStrategy().isDataCacheable(loadData.fetcher.getDataSource()) || helper.hasLoadPath(loadData.fetcher.getDataClass()))) { started = true ; startNextLoad(loadData); } } return started; }
startNextLoad里面使用loadData.fetcher启动资源的加载,完成后回调onDataReadyInternal:
1 2 3 4 5 6 7 8 9 10 11 12 private void startNextLoad (final LoadData<?> toStart) { loadData.fetcher.loadData( helper.getPriority(), new DataCallback <Object>() { @Override public void onDataReady (@Nullable Object data) { if (isCurrentRequest(toStart)) { onDataReadyInternal(toStart, data); } } ...); }
但是值得注意的是Fetcher的加载完成并不是把图片文件下载完成,只是打开了文件流而已,需要等待后面的流程从里面读取:
1 2 3 4 5 6 7 8 public class HttpUrlFetcher implements DataFetcher <InputStream> { public void loadData (@NonNull Priority priority, @NonNull DataCallback<? super InputStream> callback) { ... InputStream result = loadDataWithRedirects(glideUrl.toURL(), 0 , null , glideUrl.getHeaders()); callback.onDataReady(result); ... } }
LoadPath 看回时序图可以知道,DataFetcher的数据是被LoadPath读取去解码的。这里面也很复杂,但是我们并不需要全部了解,我这只讲个比较重要的东西。
LoadPath.load方法最终会调用到LoadPath.decodeResourceWithList方法。顾名思义它是遍历解码器列表查找一个解码器去解码文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private Resource<ResourceType> decodeResourceWithList (...) throws GlideException { Resource<ResourceType> result = null ; for (int i = 0 , size = decoders.size(); i < size; i++) { ResourceDecoder<DataType, ResourceType> decoder = decoders.get(i); ... DataType data = rewinder.rewindAndGet(); if (decoder.handles(data, options)) { data = rewinder.rewindAndGet(); result = decoder.decode(data, width, height, options); } ... if (result != null ) { break ; } } ... return result; }
这些解码器是哪里注册的呢?答案还是Glide的构造函数里面那坨很长的append,没错那坨append不仅注册了ModelLoader还注册了解码器:
1 2 3 4 5 6 registry .append(ByteBuffer.class, new ByteBufferEncoder ()) .append(InputStream.class, new StreamEncoder (arrayPool)) .append(Registry.BUCKET_BITMAP, ByteBuffer.class, Bitmap.class, byteBufferBitmapDecoder) .append(Registry.BUCKET_BITMAP, InputStream.class, Bitmap.class, streamBitmapDecoder) ...
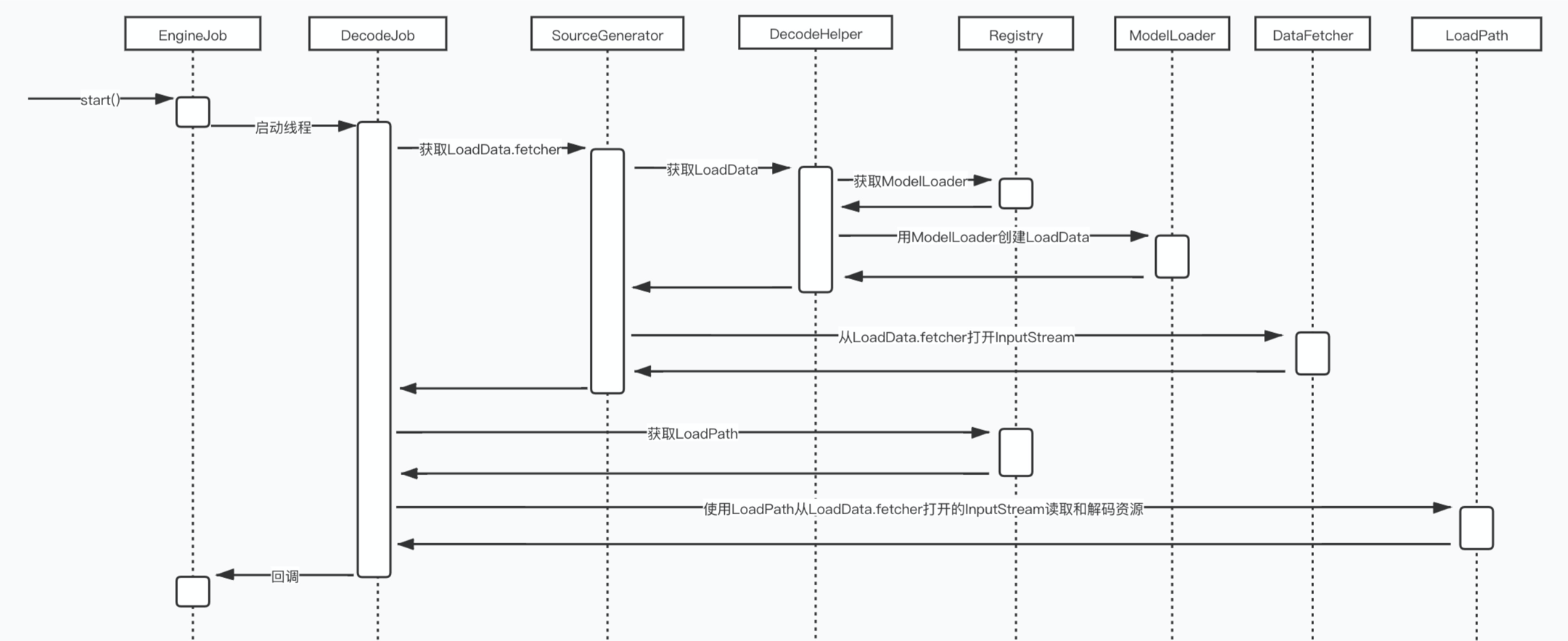
总结 之后的流程就是不断回到到Engine去放到弱引用缓存里面的。到这里整个网络资源的下载解码流程也就讲完了,我们来看看简化之后的时序图: