什么是责任链模式 责任链模式是一种对象的行为模式,它包含了一些命令对象和一系列的处理对象。是一种链型的结构,每个处理对象可以处理特定的命令对象,当遇到不能处理的命令对象的时候,就会把它传递给下一个处理对象,直到没有最后一个处理对象。
责任链模式的实现 从责任链模式的定义来看,使用单链表去实现它是一种最容易想到和最形象的做法。假设我们有一个解压程序,它可以解压多种不同的压缩格式。
数据定义成下面的样子:
1 2 3 4 5 6 struct Data { Data (unsigned char * data, int size) :data (data), size (size) {} unsigned char * data; unsigned int size; };
每个解压器类根据自己是否能够解压接收到的数据,判断应该直接解压数据还是传递给下一个解压器程序去解压。所以将这一逻辑抽象出来,我们可以得到下面的抽象基类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Decompressor {public : Decompressor () : mSuccessor (0 ){} Decompressor (const Decompressor* successor) : mSuccessor (successor){} void setSuccessor (const Decompressor* successor) mSuccessor = successor; } Data decompress (const Data& data) const { if (canDecompress (data)){ return doDecompress (data); }else if (mSuccessor!=0 ){ return mSuccessor->decompress (data); } return Data (0 , 0 ); } private : const Decompressor* mSuccessor; virtual bool canDecompress (const Data& data) const 0 ; virtual Data doDecompress (const Data& data) const 0 ; };
我们模拟三种数据的解压器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class GZipDecompressor : public Decompressor{public : GZipDecompressor () { } GZipDecompressor (Decompressor* successor):Decompressor (successor) { } private : virtual bool canDecompress (const Data& data) const cout<<"GZipDecompressor:canDecompress" <<endl; const char * d = (const char *)data.data; return d && 0 ==strncmp (d, "gzip" , strlen ("gzip" )); } virtual Data doDecompress (const Data& data) const cout<<"GZipDecompressor:doDecompress" <<endl; const char * d = "doDecompress by GZipDecompressor" ; return Data ((unsigned char *)d, strlen (d)); } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class RarDecompressor : public Decompressor{public : RarDecompressor () { } RarDecompressor (Decompressor* successor):Decompressor (successor) { } private : virtual bool canDecompress (const Data& data) const cout<<"RarDecompressor:canDecompress" <<endl; const char * d = (const char *)data.data; return d && 0 ==strncmp (d, "rar" , strlen ("rar" )); } virtual Data doDecompress (const Data& data) const cout<<"RarDecompressor:doDecompress" <<endl; const char * d = "doDecompress by RarDecompressor" ; return Data ((unsigned char *)d, strlen (d)); } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class ZipDecompressor : public Decompressor{public : ZipDecompressor () { } ZipDecompressor (Decompressor* successor):Decompressor (successor) { } private : virtual bool canDecompress (const Data& data) const cout<<"ZipDecompressor:canDecompress" <<endl; const char * d = (const char *)data.data; return d && 0 ==strncmp (d, "zip" , strlen ("zip" )); } virtual Data doDecompress (const Data& data) const cout<<"ZipDecompressor:doDecompress" <<endl; const char * d = "doDecompress by ZipDecompressor" ; return Data ((unsigned char *)d, strlen (d)); } };
嗯哼,是否直观的实现方式。最后是main函数和输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int main () RarDecompressor rarDecompressor; GZipDecompressor gzipDecompressor (&rarDecompressor) ; ZipDecompressor zipDecompressor (&gzipDecompressor) ; Data input ((unsigned char *)"gzip" ,strlen("gzip" )) ; Data output = zipDecompressor.decompress (input); if (output.data){ const char * out = (const char *)output.data; cout<<"result : " <<out<<endl; }else { cout<<"result : null" <<endl; } return 0 ; }
ZipDecompressor:canDecompress
可以看到,数据经过了ZipDecompressor和GZipDecompressor,最后由GZipDecompressor解压处理,整个过程没有经过RarDecompressor
当然为了使代码可维护性更高,我们可以再编写一个SuperDecompressor类来包装解压操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class SuperDecompressor {public : Data decompressCompressedFile (const Data& data) ; private : ZipDecompressor mZipDecompressor; RarDecompressor mRarDecompressor; GZipDecompressor mGZipDecompressor; }; Data SuperDecompressor::decompressCompressedFile (const Data& data) { mZipDecompressor.setSuccessor (&mGZipDecompressor); mGZipDecompressor.setSuccessor (&mRarDecompressor); mRarDecompressor.setSuccessor (0 ); return mZipDecompressor.decompress (data); }
这个时候main函数会显得比较简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int main () SuperDecompressor decompressor; Data input ((unsigned char *)"gzip" ,strlen("gzip" )) ; Data output = decompressor.decompressCompressedFile (input); if (output.data){ const char * out = (const char *)output.data; cout<<"result : " <<out<<endl; }else { cout<<"result : null" <<endl; } return 0 ; }
输出的结果是一样的:
ZipDecompressor:canDecompress
优化 依靠我们程序员的直觉,下面两段代码都是很容易出错的,尤其是当Decompressor的数目很多的时候。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int main () RarDecompressor rarDecompressor; GZipDecompressor gzipDecompressor (&rarDecompressor) ; ZipDecompressor zipDecompressor (&gzipDecompressor) ; Data input ((unsigned char *)"gzip" ,strlen("gzip" )) ; Data output = zipDecompressor.decompress (input); if (output.data){ const char * out = (const char *)output.data; cout<<"result : " <<out<<endl; }else { cout<<"result : null" <<endl; } return 0 ; }
1 2 3 4 5 6 7 Data SuperDecompressor::decompressCompressedFile (const Data& data) { mZipDecompressor.setSuccessor (&mGZipDecompressor); mGZipDecompressor.setSuccessor (&mRarDecompressor); mRarDecompressor.setSuccessor (0 ); return mZipDecompressor.decompress (data); }
其实使用构造函数和setter方法设置下一个处理类有一个很大的问题,就是在编码的时候很容易就写错了,会出现一些意想不到的bug,而且比较难发现。同时,每次需要修改处理类的顺序或者删除其中的一个或几个处理类,都需要使用setter方法对处理链进行修改,不仅繁琐,而且也比较容易出错。
基于以上的原因,我们会去想,有没有一种更加灵活的实现方式,使得构建处理链不容易出错,而且也能很简单而且很安全的修改处理链呢?
其实我们可以用下面的链式结构去优化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Decompressor {public : Decompressor () : mSuccessor (0 ){} Decompressor& next (Decompressor& successor) { mSuccessor = &successor; successor.setSuccessor (0 ); return successor; } Data decompress (const Data& data) const { if (canDecompress (data)){ return doDecompress (data); }else if (mSuccessor!=0 ){ return mSuccessor->decompress (data); } return Data (0 , 0 ); } private : const Decompressor* mSuccessor; virtual bool canDecompress (const Data& data) const 0 ; virtual Data doDecompress (const Data& data) const 0 ; void setSuccessor (const Decompressor* successor) mSuccessor = successor; } };
在这里,我们添加了一个next方法,同时把setSuccessor设为private,于是使用的方法就会变得简洁了许多。
1 2 3 4 Data SuperDecompressor::decompressCompressedFile (const Data& data) { mZipDecompressor.next (mGZipDecompressor).next (mRarDecompressor); return mZipDecompressor.decompress (data); }
另一种灵活的实现方式 联想一下linux的管道机制:前一个命令的结果会传递给后一个命令 。
是不是可以从中得到启发呢?是不是可以有一种架构可以使得通过下面的形式就能得到最终处理后的结果?
1 Data decompressedData = compressedData | mZipDecompressor | mGZipDecompressor | mRarDecompressor;
首先,很容易想到我们需要通过重载操作符去实现这种机制。我们可以重载 “|” 操作符,将Data和Decompressor作为参数传入,再将处理后或者没有处理的Data作为返回值返回,传到下一个Decompressor那里去。
基本的思想是这样的,但是这里有个很重要的问题要处理:我们如何知道上一个Decompressor有没有解压过数据?
当然可以直接调用Decompressor::canDecompress看看是否是可解压的就能知道上一个Decompressor有没有处理过数据。但是这样的处理模式有一些风险,而且也比较浪费资源,明明前一个Decompressor已经解压完成了,但是后面的Decompressor还回去判断是否可以解压,这个判断可能比较复杂。
第二种解决方案就是拓展Data结构体,添加一个是否已经解压字段。这样能够完美的解决问题,但是Data的职责就变重了,他不仅要保存数据,还要知道保存的数据究竟是解压过的还是没有解压过的。而且这个标志字段只有在解压的过程中才有用,因为一般数据在存储的时候我们已经知道它是否被压缩过了,我们总不会会将未解压和解压过的数据混在一起存放的。
其实还有第三种解决方法:
1 2 3 4 5 6 struct DataWrapper { DataWrapper (const Data& data) : data (data),isDecompressed (false ) {} Data data; bool isDecompressed; };
在DataWrapper添加了一个属性isDecompressed来标志数据是否已经解压。这个Wrapper可以只在解压过程中临时使用,不影响数据的存储。
然后实现的重点就是重载操作符了,其实它的实现很简单:
1 2 3 4 5 6 7 8 DataWrapper& operator | (DataWrapper& data, const Decompressor& decompressor){ if (!data.isDecompressed && decompressor.canDecompress (data.data)){ data.data = decompressor.doDecompress (data.data); data.isDecompressed = true ; } return data; }
现在Decompressor就只需要提供判断是否可以解压和进行解压的功能。所以我们可以将Decompressor基类简化下面这样。其实这样的Decompressor就相当于java里面的接口了,面向接口编程可以使得业务逻辑更加清晰,而且也更易于维护。
1 2 3 4 5 class Decompressor {public : virtual bool canDecompress (const Data& data) const 0 ; virtual Data doDecompress (const Data& data) const 0 ; };
所以我们的SuperDecompressor类就可以写成下面的样子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class SuperDecompressor {public : Data decompressCompressedFile (const Data& data) ; private : ZipDecompressor mZipDecompressor; RarDecompressor mRarDecompressor; GZipDecompressor mGZipDecompressor; }; Data SuperDecompressor::decompressCompressedFile (const Data& data) { DataWrapper wrapper (data) ; wrapper | mZipDecompressor | mGZipDecompressor | mRarDecompressor; return wrapper.isDecompressed ? wrapper.data : Data (0 ,0 ); }
而main函数是一样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int main () SuperDecompressor decompressor; Data input ((unsigned char *)"gzip" ,strlen("gzip" )) ; Data output = decompressor.decompressCompressedFile (input); if (output.data){ const char * out = (const char *)output.data; cout<<"result : " <<out<<endl; }else { cout<<"result : null" <<endl; } return 0 ; }
输出结果如下:
ZipDecompressor:canDecompress
所以如果我们现在需要将SuperDecompressor拓展成一个真正万能的解压类,不仅能解压压缩文件,也能解压图片,还能解压Base64编码的超级解压类也很简单了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class SuperDecompressor { Data decompressUnknowType (const Data& data) ; Data decompressImage (const Data& data) ; Data decompressCompressedFile (const Data& data) ; Data decompressBase64 (const Data& data) ; private : ZipDecompressor mZipDecompressor; RarDecompressor mRarDecompressor; GZipDecompressor mGZipDecompressor; JpgDecompressor mJpgDecompressor; PngDecompressor mPngDecompressor; Base64Decompressor mBase64Decompressor; }; Data SuperDecompressor::decompressUnknowType (const Data& data) { DataWrapper wrapper (data) ; wrapper | mZipDecompressor | mRarDecompressor | mGZipDecompressor | mJpgDecompressor | mPngDecompressor | mBase64Decompressor; return wrapper.isDecompressed ? wrapper.data : Data (0 ,0 ); } Data SuperDecompressor::decompressImage (const Data& data) { DataWrapper wrapper (data) ; wrapper | mJpgDecompressor | mPngDecompressor; return wrapper.isDecompressed ? wrapper.data : Data (0 ,0 ); } Data SuperDecompressor::decompressCompressedFile (const Data& data) { DataWrapper wrapper (data) ; wrapper | mZipDecompressor | mRarDecompressor | mGZipDecompressor; return wrapper.isDecompressed ? wrapper.data : Data (0 ,0 ); } Data SuperDecompressor::decompressBase64 (const Data& data) { DataWrapper wrapper (data) ; wrapper | mBase64Decompressor; return wrapper.isDecompressed ? wrapper.data : Data (0 ,0 ); }
当然,这种处理方式在数据已经被解压的情况下依然会传给下一个解压器,直到经过了整条处理链。所以会造成一定的资源浪费。
责任链模式的实际应用场景 责任链模式的实际应用,最广为人知的就是安卓View的Touch事件的传递机制了。其实这是一种双向的责任链模式。在接收到Touch事件的时候,父View会通知子View,如果子View不处理,父View才去处理。光说可能有点难懂,我们直接看源码吧:
1 2 3 4 5 6 7 8 9 10 11 12 13 public boolean dispatchTouchEvent (MotionEvent ev) { boolean result = false ; if (!onInterceptTouchEvent(ev)) { result = child.dispatchTouchEvent(ev); } if (!result) { result = onTouchEvent(ev); } return result; }
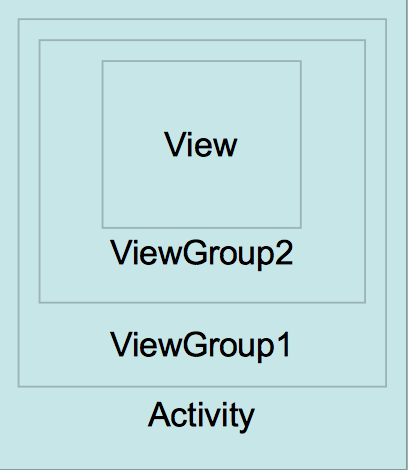
代码看起来也不好懂?没关系,我用个实际的例子解释一下就明白了。首先我们有下面的一个Activity:
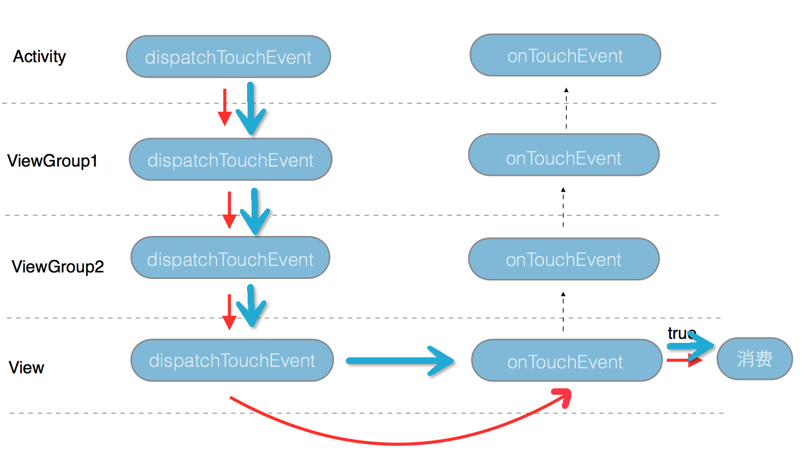
当我们点击最中间的那个View的时候Touch事件的传递过程如下图:
Touch事件通过Activity、ViewGroup1、ViewGroup2的dispatchTouchEvent方法最后到达View的dispatchTouchEvent方法,在View被处理,所以返回true。于是Activity、ViewGroup1、ViewGroup2的dispatchTouchEvent方法都会直接返回,而不会调用处理方法onTouchEvent
总结 这一部分本来应该讲一讲责任链模式的优缺点的,但是我自己其实不太喜欢这样的总结性的东西。所以还是留给读者自己体会吧。